

足球比赛结果预测模型是利用数据科学和机器学习技术,对足球比赛的胜负、比分等结果进行预测的一种新型工具。该模型通过分析历史比赛数据、球员状态、球队战术、场地条件等多方面因素,构建出精确的预测模型,为球迷和体育从业者提供有价值的参考。,,该模型的应用不仅提高了预测的准确度,还为体育竞技领域带来了新的发展机遇。通过深入挖掘和分析比赛数据,可以更好地理解比赛规律和球员表现,为球队的战术制定和球员选材提供科学依据。该模型还可以应用于赛事转播、广告投放、体育彩票等领域,为相关产业带来巨大的商业价值。,,足球比赛结果预测模型也面临着数据质量、模型精度、道德伦理等方面的挑战。在应用该模型时需要谨慎对待,确保其准确性和可靠性,同时也要遵守相关法律法规和道德规范。
在当今这个数据驱动的时代,足球这一全球最受欢迎的体育项目也不例外,正经历着前所未有的变革,随着大数据、机器学习和人工智能技术的飞速发展,足球比赛结果预测模型逐渐成为现实,不仅为球迷提供了更为精准的观赛体验,也为俱乐部管理、球员评估和赛事组织带来了革命性的变化,本文将深入探讨足球比赛结果预测模型的发展现状、技术原理、应用场景以及面临的挑战与未来展望。
一、足球比赛结果预测模型的发展背景
传统上,足球比赛的结果往往被视为不可预测的“黑箱”,依赖于教练的战术布置、球员的即时状态、对手的实力以及赛场上的不可预知因素,随着数据收集技术的进步,如GPS追踪系统记录球员跑动数据、社交媒体分析球员情绪变化、历史比赛数据分析等,足球比赛的“数据足迹”日益丰富,这些数据为构建预测模型提供了坚实的基础。
二、技术原理与模型构建
1. 数据收集与预处理
模型构建的第一步是收集全面的数据集,包括但不限于球队历史交锋记录、球员伤病情况、近期比赛表现、球员个人数据(如进球数、助攻数)、球队战术风格、场地条件等,随后,进行数据清洗和预处理,去除异常值和噪声,确保数据的准确性和可靠性。
2. 特征选择与工程
在众多数据中,选择对比赛结果有显著影响的特征是关键,这可能包括球队的近期胜率、主场优势、球员的体能状态、对手的防守强度等,通过特征工程,如归一化、标准化、缺失值处理等,提高数据的可用性。
3. 模型选择与训练
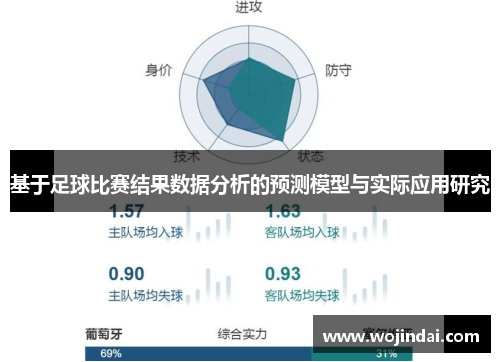
根据数据的特性和预测需求,可以选择不同的机器学习算法,如逻辑回归、支持向量机、随机森林、神经网络等,这些算法通过学习历史数据中的模式,试图捕捉影响比赛结果的复杂因素,训练过程中,通过交叉验证等方法评估模型的性能,并进行调优。
4. 预测与解释
模型训练完成后,即可对未来的比赛结果进行预测,预测结果可以是胜负概率、比分预测等,为了提高模型的透明度和可解释性,可以结合特征重要性分析,解释哪些因素对预测结果影响最大。
三、应用场景与实际效果
1. 球迷体验
对于普通球迷而言,足球比赛结果预测模型提供了更为精准的赛前分析,帮助他们做出更明智的观赛决策,如选择投注或制定观赛计划,这些模型还能提供赛前热身、球员表现分析等内容,丰富观赛体验。
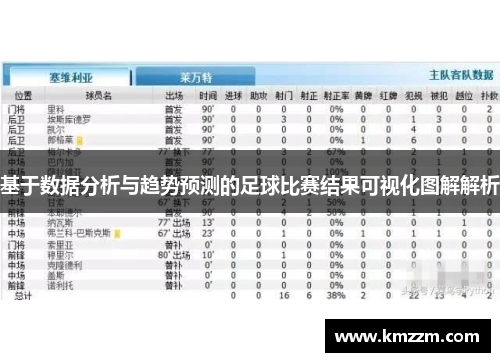
2. 俱乐部管理
对于足球俱乐部而言,预测模型有助于管理层进行战术调整、球员引进和转会决策,通过分析对手的强弱点,俱乐部可以制定更有针对性的训练计划和比赛策略,提高球队的整体竞争力。
3. 赛事组织与转播
在赛事组织层面,预测模型可以帮助主办方更准确地估计观众数量和门票销售情况,优化场馆安排和安全措施,对于转播方而言,预测模型能提前预测热门比赛和潜在的高收视率时段,优化转播资源和广告投放策略。
四、面临的挑战与未来展望
尽管足球比赛结果预测模型展现出巨大的潜力和价值,但其发展仍面临诸多挑战:
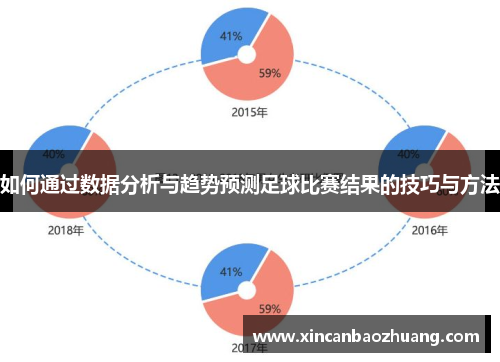
数据质量与隐私:如何确保数据的准确性和合法性,同时保护球员和俱乐部的隐私权,是亟待解决的问题。
模型泛化能力:足球比赛受多种不可控因素影响,如何提高模型的泛化能力,使其在各种不同情境下都能保持较高准确率,是技术上的难点。
伦理与公平性:预测模型可能加剧比赛结果的“可预测性”,引发对比赛公平性和观赏性的担忧,需在技术进步与体育精神之间找到平衡点。
技术创新与融合:随着AI技术的不断进步,如深度学习、自然语言处理等技术的融合应用,将进一步推动预测模型的精准度和实用性。
足球比赛结果预测模型是数据科学与体育竞技结合的产物,它不仅为球迷提供了全新的观赛体验,也为俱乐部管理和赛事组织带来了前所未有的机遇,尽管面临诸多挑战,但随着技术的不断成熟和应用的深入探索,这一领域必将迎来更加辉煌的未来,它不仅将改变我们对足球的理解和欣赏方式,更将促进体育产业乃至整个社会在数据驱动下的创新发展。




 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号